Do I Have Enough Data to Optimize My Campaigns?
May 7, 2018Is there a minimal amount of data required for campaign optimization? We have a definitive answer.
And that answer is always yes; an affirmative, absolute and positive yes – regardless of how much data is available.
To best see why, consider Pequod Inc., a supplier of fresh organic, locally sourced whale milk and dairy products. The marketing team sent out two email variants last week, promoting their new premium white whale crème fraiche. Each variant was sent to a hundred clients. Five of the clients who received variant A made a purchase, versus seven who received variant B.
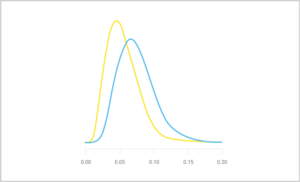
There’s no conclusive winner here. Assuming a non-informative prior, the conversion rate posterior for variant A is plotted below in yellow, with its mode – the most likely value for the underlying conversion rate – close to 5%. Variant B is in blue, with its mode close to 7%. With so little data available, many other possible conversion rates are also likely, so both distributions are quite broad.
This large variance in the inferred underlying conversion rates has a devastating effect on the precision of the difference between the two variants, namely B’s performance minus A’s, which comes out way too wide for deciding on a winner:
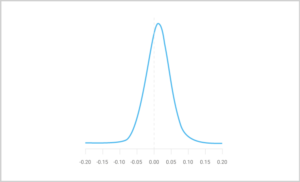
Clearly, even fairly low credible intervals include both sides of zero in this example; similarly, alternative hypotheses – that variant A outperforms B or that the underlying conversion rates are actually identical – cannot be rejected at any reasonable significance level.
Nevertheless, the probability that variant B outperforms A clocks in at over 72% (the area under the curve to the right of the dashed line at zero). Ignoring this fact altogether means Pequod will sell less of their lovely cream when the next batch of emails gets sent. Looking at the campaign and the variants as a multi-armed bandit problem, a simple strategy – Thompson sampling – presents itself as a natural way to strike a balance between exploiting the fact that variant B seems to perform better than variant A, versus exploring the possibility that, given some more data, variant A will prove itself superior. In this case, the expected improvement to the overall conversion rate of the campaign is a very respectable 7.4% when compared to continuing a 50-50 split between the variants.
Using such adaptive strategies means optimization starts long before “conclusive” results can be made. In fact, the optimization starts immediately with the launch of the campaign, and the probabilities of each variant outperforming the others are continuously updated with each new data point arriving. Even better, such strategies self-correct when variants performance changes over time, converging quickly on the new optimal split.
In other words, no matter how much data is available, one can always calculate the best next split between variants such that the expected performance is maximized throughout the lifetime of a campaign. Taking advantage of early results, neither ignoring nor overstating their uncertainty, is an easy way to boost results of any campaign – requiring no additional resources from the marketing team. So, do you have enough data to optimize your campaigns? The answer is always yes; an affirmative, absolute and positive yes.