The Future of Customer Data Platforms: To Bundle or Not to Bundle?
March 23, 2023Bundling vs. unbundling set the data world ablaze in February, and the debate quickly made its way to Customer Data Platforms. These recent conversations are the latest logs on a fire that’s been burning for a long time. The cable industry is a classic example, and that debate is far from over. 10 years ago, the same discussion unfolded in martech. New martech vendors were pushing to bundle all channels into one vertically integrated solution while the legacy vendors fought to protect their territory. We all know how that ended.
Interestingly, the CDP world now finds itself in a similar place– legacy vendors are trying to protect their bundling whereas newer vendors (mostly on the data infra side) are pushing their own agenda with unbundling.
But let’s not make this an ideological debate. Let’s look at it on a more fundamental level. We’ll use two questions to cut straight to the point: What are the limitations of the traditional bundled CDP, and what problems are we trying to solve with unbundling? First, let’s establish a basic understanding of what constitutes a CDP.
The building blocks of a customer data platform
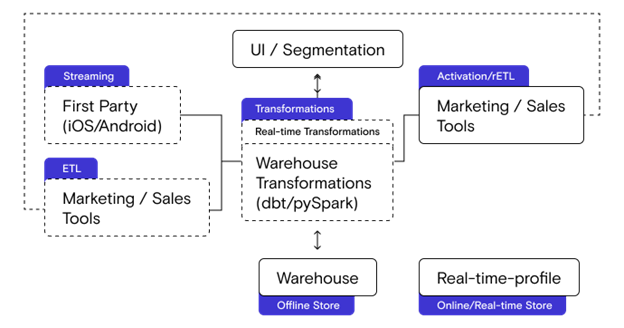
The diagram above represents the major building blocks of any CDP. Let’s break each of these down:
- Streaming: Streaming tools collect first party data, like clickstream events, from websites, mobile apps, and PoS devices.
- ETL: ETL tools collect customer data from different SaaS tools like CRMs, ad tools (campaign data), and marketing tools (audience/cohort data) and send the data to the warehouse.
- Transformations: At a high level, this represents any custom logic applied to the customer data to change it in some way. Transformations can further be classified into:
- Real-time transformations: these are typically used to update the source data in-stream and in “real-time” before sending to different destinations.Typical use cases include PII removal, fixing events, and enhancing events with additional meta-data.Simple batch transformations: these are basic computations done to user attributes while the data is “at rest”, i.e., in the warehouse. These are commonly known as computed attributes. Examples include computing total_revenue, total_num_of_logins, etc.Complex batch transformations: these are warehouse transformations that require more computation. The most common example for customer data is user identity stitching which requires computing transitive closure on the identity graph and while can be done in SQL, is quite complex.ML transformations: for more advanced use cases, one may want to compute predictive features like churn scores, product recommendations, etc. on a per user basis.
- Activation: Activation involves sending the transformed data to different marketing and product SaaS destinations. Activation integrations can be of different types – some may stream data in real-time to destinations from different first party and ETL sources, other more batch-oriented integrations may send audiences and attribute data from the warehouse to destinations. This latter category is commonly known as Reverse ETL.
- UI / Segmentation: Most marketing oriented CDPs offer a graphical user interface where marketing and product teams who don’t want to write code can create workflows around audience segmentation, journey, orchestration, etc. Conceptually, they provide a visual abstraction over the transformation box shown above. Whether this component is essential to the CDP or should be part of a downstream marketing automation system is up for debate.
To support the non-real time transformation use cases highlighted above, a CDP needs to keep a copy of all the data including user attribute data, event data, and computed traits. Two kinds of stores are typically used to keep this state:
- Offline store: Non-real time batch transformations are run on top of the offline store, a store such as a data-warehouse or a data-lake .
- Online / Real-time store: Real-time stores, like Redis, keep the user profile and serve them over an API to be used for in-app personalization.
One non-CDP component that’s important to note is the loop-back system to send data from SaaS tools back into the CDP. While not traditionally a part of the CDP itself, loop-back of data is critical for end to end attribution of marketing actions. e.g. measuring the success of an email campaign after the email is sent out. CDPs should be able to do more than just activate the data. They should be able to feed post activation data and analysis back into the system.
Every CDP, bundled or unbundled, should offer all of the above functionality. Traditionally, CDPs have included everything in a single vertically integrated solution. This approach made sense when use cases were limited and marketing teams were the primary owner of the CDP. But this approach doesn’t cut it for today’s use cases.
Limitations of the traditional bundled customer data platform
The biggest limitation of the vertically integrated approach is that it leads to an inflexible data architecture that is difficult to adapt to as a company grows in its Data Maturity Journey. As companies become digital first and marketing stacks get more complex, so does the need for more sophisticated use cases on top of customer data. Think of things like user journeys, attribution, ML models for churn prediction, and product recommendations. These use cases require the expertise of the data analysts and data scientists from engineering or data teams. But the traditional black-box CDP was created for marketing teams, not engineers, so they don’t expose the customer data in a manner conducive to build applications for these more sophisticated use cases.
Another limitation of the traditional CDP is its inability to bring data from other systems into its profiles. This data is typically collected via ETL pipeline into the data-warehouse, which the traditional CDP cannot access.
Data privacy and retention concerns make matters worse for the traditional CDP which typically stores PII and other sensitive information inside of its black box.
The limitations of these bundled systems led many data teams to build another, redundant, customer data stack in parallel to Marketing’s CDP. This parallel stack typically had all the pieces of a CDP covered above but implemented in a brittle, if more capable system.The stack includes the data collection layer to collect first party sources in a data warehouse or data lake, a transformation layer written in SQL/python/spark to process the data, and an activation layer to push the data out to different marketing tools including the marketing CDP. Engineering often would build the collection and activation layers using home grown scripts or open-source solutions.
Believe it or not, running two parallel customer data stacks is never a good idea. It causes massive duplication of data and effort, resulting in burgeoning costs. Moreover, it proliferates data silos, the problem that CDPs were built to solve in the first place, because the systems don’t share data. For example, the cohorts developed by the marketing team in their CDP are not visible in the data-team’s customer data stack while the ML outputs like churn score are not visible in marketing’s CDP. The only thing worse than not having a CDP is having two CDPs! This “two CDP” environment is fueling today’s bundling vs. unbundling debate. To overcome the limitations of the traditional, bundled CDP, unbundling is the right move, but there’s more than one way to unbundle the CDP. In part two, we’ll delve into detail on two approaches to unbundling.
This article was originally published on RudderStack’s website. Click here to see the original blog post.