The Future of Customer Data Platforms: Unbundling the Right Way
March 30, 2023To understand the push to unbundle the CDP, it’s important to understand why we’re here in the first place. In part one of The Future of Customer Data Platforms, we unpacked the limitations of the traditional, bundled approach to the Customer Data Platform. Giving a nod to Chesterton’s Fence, we articulated why the bundled CDP came about and detailed why it’s not fit for modern use-cases. This analysis led us to the conclusion that it is time to unbundle the Customer Data Platform, but there’s more than one way to unbundle your CDP.
The key motivation for unbundling is to expose customer data so that data analysts and scientists can build more sophisticated use cases such as marketing attribution, churn prediction, and product recommendations. Ideally, this would be done without having concerns around syncing customer data between your CDP and your cloud data warehouse. However, unbundling comes with trade offs. Unbundle the wrong way, and you run the risk of creating more problems than you solve.
Here, we’ll unpack two different approaches to unbundling and make a case for a three-layer decoupling rather than a wholesale unbundling.
Unbundling the CDP the wrong way
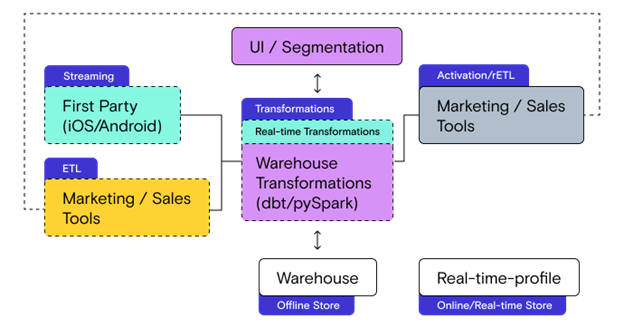
As represented by the different colors in the diagram above, one tempting way to unbundle the CDP is to use a separate product for each of the boxes:
- Streaming (and real-time transformations)
- ETL
- Warehouse Transformations and UI/Segmentation
- Activation/rETL
- Storage
This approach makes for a pretty diagram, but putting it into practice is a nightmare. For starters, procuring tools from multiple vendors creates an unnecessary management burden. You have to update config in multiple tools to set up an end to end connection from a source to a cloud destination. And this leads to observability and debugging headaches. If something goes wrong, you’ll have to check multiple dashboards, and you could end up having to connect with multiple support teams to fix the issue.
More importantly, these glued together solutions do not support some critical data paths. Because the tools don’t talk to each other directly, they require the data warehouse as an intermediary (as a source or a destination), which means they cannot support real-time streaming use cases. This is a deal breaker for any company that may implement real-time personalization now or in the future.
Also, because each vendor only sees a fraction of the customer data, critical transformations like identity stitching and creating the user-table (“customer 360”) require custom SQL/python code. This non-trivial lift is offered out of the box by bundled CDPs.
Unbundling the CDP the right way
To create the most robust and capable customer data stack, we believe unbundling is best accomplished by decoupling three layers:
- Storage layer: By decoupling the storage layer, you eliminate data silos to avoid different versions of the same customer data stored in different tools. This is the whole premise behind the warehouse-first approach.
- Transformation layer: Providing flexibility around user-defined transformations is critical in enabling customers to unlock basic use cases (such as computing total_revenue) to advanced use-cases (such as computing predictive features).
- Integration, Real-Time Transformation, and Activation layer: At a high level “integration” refers to the movement of data from source to destination. Reverse ETL (or “activation”) is a subset of integration and refers to moving data from the warehouse to a downstream destination. Decoupling these two results in integration challenges which typically surface when you want to add a new field to the customer record – if decoupled, you have to make configuration changes manually across your entire stack. We include real-time transformations here as the data is transformed while it is “in-flight”.
Keeping the Integration, Activation, and Real-time transformation layer interlinked, as shown in the diagram below, is the key.
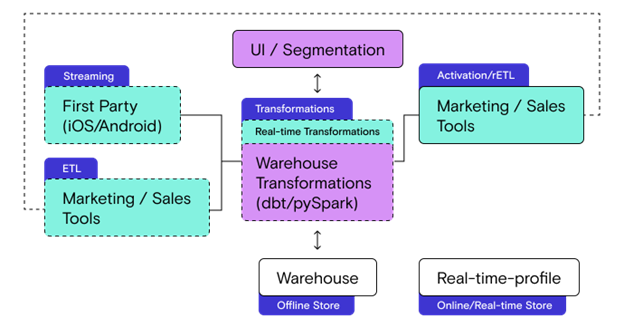
Delivering integration, activation, and real-time transformations on the same platform provides a number of benefits:
- Seamless Integration into Marketing and Product Tools: You can integrate from every data source to every SaaS destination without having to set up configs across multiple tools.
- Support for real-time and batch: Every CDP use case is unlocked, including those requiring real-time integration into marketing and product tools.
- Automated Identity Stitching and Customer 360: You get the promise of a complete user table without having to manage complex data models and pipelines stitching data between different vendors. Because the platform understands all the data models for every pipeline, it can deliver identity stitching and customer360 out of the box.
- Single Observability Plane: Ensuring the health of your data pipelines is easier with a single observability plane for monitoring, alerting, and triaging issues. It reduces engineering overhead and streamlines the triage process, accelerating time to resolution.
At RudderStack, we’re solving the integration pain-point regardless of source or destination, unconcerned with the pipeline nom-du-jour. We believe customers are best served by a transparent, flexible, and extensible integration solution that enables data teams to solve their most pressing pain-points (e.g., getting data from point A to point b) without losing sight of future business needs (e.g., predictive modeling).
This article was originally published on RudderStack’s website. Click here to see the original blog post.