Avoiding the identity resolution trap
February 28, 2022The way in which you perform identity resolution can have a profound impact on the customer experiences you’re able to deliver. If your goal is to deliver personalized, privacy-compliant experiences at scale, here are three identity resolution mistakes you need to avoid.
Articulation of Customer Data Platform (CDP) value typically centers on ingestion, segmentation, and activation. Core to all of those processes is identity resolution. Identity resolution plays a prominent role in organizing customer data for faster and better segmentation, and more accurate customer journey analytics.
As the concept of identity is central to managing and merging customer data, it’s important to clarify a number of misconceptions.
A quick primer
Unlike other types of data, customer data requires specific treatment and structure to effectively power the use cases required by the consumers of that data. Customer data is typically organized by creating a record of a natural person and their associated digital identities, along with relevant behaviors and preferences. Contrary to some belief, the need isn’t to ingest every data object, but rather the data objects that matter. What matters typically maps to a specific set of needs from the business.
Identity resolution is a set of dynamic merging rules that govern how data is assigned on arrival—whether incoming data should be used to create a new user record or appended to an existing user record. The logic behind identity resolution works by creating a waterfall of various identities such as email, device IDs, mobile number, cookie ID, customer ID, third party IDs etc to merge user information based on the presence of the identities in the data payload. The sequence in the hierarchy can have profound effects, but more on this in a bit.
The overall quality of a company’s customer data depends (in part) on the ability to accurately match and merge customer records across various sources and systems. For clarity, the other components of data quality relate to structure and integrity.
There are two distinct ways to do identity resolution: deterministic matching and probabilistic matching.
Deterministic matching works by merging customer information exclusively in the presence of two or more of the same identities. The approach is fairly conservative in nature to ensure data integrity.
Probabilistic matching aims to merge customer profiles in the absence of a direct match by looking at other signals, and assigning both a score to the strength of those signals and a rule that merges data based on the strength of the scores. The desired benefit is scalable personalization. Probabilistic matching is nothing new; Master Data Management (MDM) solutions have had fuzzy matching based on name and address for decades, while device fingerprinting has been a popular technique in the ad tech world for the past decade or so.
Identity resolution is a critical part of any customer data strategy, and while there is no shortage of views on the topic, there are some important considerations that can have a profound impact on your customer experience.
Three identity traps to avoid
There are three core principles about identity resolution that everyone needs to understand.
First rule: Probabilistic matching should NEVER be part of your core identity strategy. Probabilistic matching can be suitable for one channel (paid ads) but detrimental to most others (customer support, transactional emails, loyalty).
- Example one: Things can go from bad to worse if a customer service use case relies on customer data merged based on a probability score, and the information in the person’s transaction history is wrong.
Case in point…
- Example two: What happens when a transactional email is sent based on a probabilistic match and gets identity resolution wrong? The customer gets a receipt with someone else’s information, and their first thought is that they got hacked–a brand—ruining experience.
- Example three: An important marketing channel for most brands is loyalty. Loyalty programs rely on precise data to reward their best customers. Incorporating probabilistic matching into loyalty will ensure mismatched data and sub-optimal LTV.
Some vendors tout probabilistic matching as an important differentiator. This sounds exciting but merging records probabilistically does not have a causal relationship with value creation across channels. These vendors will reference KPIs vs benchmarks as proof, but the KPIs are questionable.
Examples include “Lifecycle stage correction for up to 25% of customers” or “30% cost savings vs. legacy identity providers.”
There are also substantial privacy concerns that need to be addressed. Commingling data is risky business, and with over a billion dollars of fines levied by the EU for GDPR related violations, brands across the globe need to tread carefully. What happens if customer data is erroneously merged and a German resident’s information leaves the EU because it appears to be tied to a US user due to false probabilistic match?
The questionable upside doesn’t outweigh the real downside.
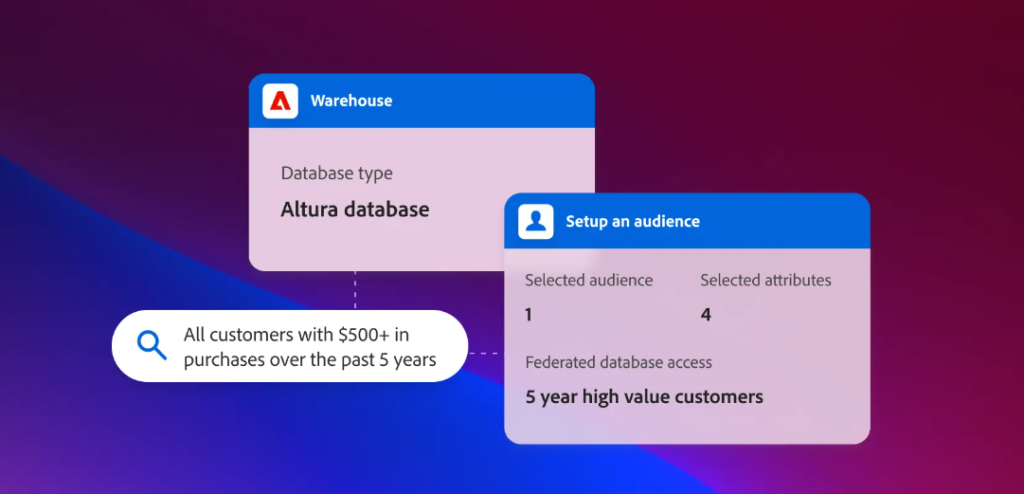
Additionally, a much better (and safer) option than mismatching data via probabilistic resolution is to apply broader segmentation rules, or to create modeled audiences.
Second rule: While identity resolution is important, it is by no means a silver bullet, and does not address the entirety of the problems teams face. When you have continuous uncertainty and chaos in the digital ecosystem, you have to figure out how to solve for the unknown unknowns.
Problem one: The digital ecosystem is in a constant state of flux. New vendors, new channels, new laws and restrictions, API updates, tracking changes, etc.
Problem two: Chaos theory applies to customer data within any organization. Due in part to external changes, event tracking needs change, campaigns are created, experiments are run, models are built, new data is continuously created and needs to be integrated throughout the stack.
Problem three: Teams wrongly assume that the problems they have today will either be the same ones they have in the future, or that they will just have more of the same problems. In reality, the problems of the future will look very little like today’s problems.
The opportunity around activation is like putting together a puzzle. The challenge is that the puzzle pieces are constantly being moved.
Third rule: Identity resolution decoupled from event collection fails to address all real-time use cases across marketing, analytics, and privacy. Whether the solution is doing simple JOINS or complex identity stitching, identity resolution has to be coupled with real-time event collection.
Doing identity stitching via a simple JOIN function misses the point and creates privacy risk. You find this approach in CDPs that aren’t doing native event collection, reverse ETL, and MDM tools.
Identity resolution has to be tied together with real-time data ingestion for a few reasons.
Reason one: Real-time customer experience requires it. Consumers have shorter attention spans than ever before. Being able to market in the moments that matter is the difference between winning and losing in today’s digital economy.
Reason two: Better customer experience is about consistency, and state transitions are not an edge case. People traverse between anonymous and known states. They switch devices and engage across multiple platforms and brand properties. This is the norm, not an afterthought.
As people move between states, modalities, and form factors; identities must be mapped in real time to maintain consistency of the customer experience. Doing identity resolution after the fact misses this reality entirely.
Reason three: Privacy matters! Privacy is a fundamental human right, and if identity resolution isn’t tightly coupled with event collection the company is at massive risk of breaking the law inadvertently.
Even within the confines of the law, being a good marketer is not the same as being creepy. Some brands may think it’s a good idea to combine data from certain channels, but that’s not always what the consumer wants and it can come across as stalkerish.
Bonus rule: Teams should have full control and visibility over how their identity strategy works. Most vendors attempt to prescribe a one-size-fits-all approach to identity resolution. That is to say, a rigid or fixed order in the waterfall.
Most digital marketing suites have identity resolution capabilities, but they’re very limited in nature. Most lack any flexibility and never contemplated use across other applications.
How can a vendor prescribe the same set of business logic when organizations may have to adhere to different regulations? Here are a couple examples:
Example one: Media companies who show video content are prohibited from merging anonymous and known profiles due to the need to adhere to VPPA. This is different from a retailer who has no such regulatory restrictions.
Example two: Many successful digital businesses run two-sided marketplaces. At mParticle we work with several of them, and some want to combine user data from both sides while others don’t. This requires flexibility to meet the specific needs of the business.