Generative AI and Personalization won’t work without a Customer Data Operations Strategy
December 18, 2023At the recent AWS re:Invent sessions, you couldn’t go anywhere without hearing about Generative AI. There was also a ton of focus on elevating experiences and personalization. What I heard less about is the importance of the quality of underlying data in making cutting edge AI or personalization tools actually work. And that’s a huge mistake.
Data quality isn’t nearly as sexy as Generative AI, but if you don’t get the input right, that magical-seeming output will be wrong. Building and iterating custom models is extremely expensive – do you want to waste time and resources building models on bad inputs? What good is the ability to customize outreach emails if the data is inaccurate? How useful is it to generate marketing messages at scale or send well-timed push notifications if the details are wrong?
The tricky thing is, “good data” isn’t a static thing. For consumer brands, it requires an ongoing end-to-end management of workflows that turn raw customer data into a valuable and usable asset to fuel customer engagement teams and tools. I like to think of it as “customer data operations.”
Unfortunately, this isn’t as easy as it sounds, and it’s more involved than many believe it to be (or than most customer data tool vendors make it out to be).
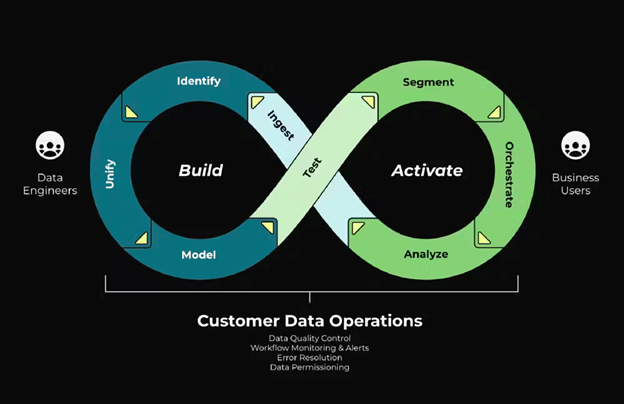
Data unification and use is not set-and-forget — it takes upkeep
Unifying customer data is a complex challenge because of the sheer volume and diversity of data points, the fragmentation of data across different siloed systems, and the lack of standardization in how data is collected.
On top of all that, customer lives are dynamic and constantly evolving, with changes in demographics, interests, and behaviors often not explicitly captured in the data you collect. This is to say nothing of the ever increasing diversity of places where this data needs to be collected as new channels continue to proliferate.
What this means is that building and maintaining unified customer profiles is not “one and done.” It’s hard enough to set up a unified customer view, but even when you accomplish that it’s only the beginning.
First is the resource-intensive job of creating a foundational customer data asset, which includes:
- Ingesting data
- Resolving known (key-based) identities
- Resolving identities for “everything else” (the data without linking keys)
- Modeling the customer data
- Shaping the customer data
- Building data workflows
Then you need to maintain steady-state functioning for that foundational asset, which involves:
- Data quality control
- Updating data assets and transformations as upstream data evolves
- Monitoring workflows
- Handling compliance obligations, including rights to erasure
- Error resolution
- Data governance
Finally, if any new data sources or downstream destinations are introduced, there needs to be a thorough process for change management, including a safe environment to test workflows so nothing breaks in production and causes costly downtime.
If there’s one thing you should take away from this article, it’s the scope and complexity of keeping your data working for you.
If you want to dig deeper, read on. I’ll lay out the elements in greater detail, along with common approaches and why they fall short.

Customer identity is difficult and specialized
Resolving identities and unifying customer data into a usable asset is time-consuming, expensive, and leaves room for error as new and often conflicting data enters the mix. But this is the critical first step toward getting all the rest of marketing and analytics to work properly — if you don’t do this right, you end up feeding downstream tools and processes with inaccurate and incomplete data.
Things get time-consuming when your approach uses custom match-merge to do identity resolution that’s slow, inaccurate, and difficult to maintain, as with legacy approaches like those in MDM or ETL solutions. Running this also requires teams to take data workflows down, often for weeks at a time.
It gets expensive if you’re outsourcing identity resolution to providers that rely on third-party data signals, which costs more and performs poorly due to rapidly deteriorating third-party fidelity. If your approach involves doing identity resolution in your data warehouse, it requires spending computing credits and the costs increase exponentially over time.
As for errors, there are common problems that lead to inaccuracies and profile collapse with both a composable CDP (Customer Data Platform) approach and packaged CDPs. When performing deterministic matching in a data warehouse, as with a naive “composable” approach, identity becomes inaccurate as PII data changes over time, and profiles aren’t guaranteed to be stable. When using a typical CDP in-product identity resolution with deterministic & probabilistic matching, quality suffers whenever the platform drops historical data. And third-party-augmented identity resolution isn’t just expensive as mentioned above, it’s also becoming less and less accurate as cookies are phased out and privacy regulations evolve.

Data needs are constantly changing
Business users constantly ask for fast access to new data sources and insights that require extensive data modeling and governance, often across multiple systems. Adding a new data source and then using that data to build an attribute and generate insights is a lot of work.
There’s significant data mapping from system to system so each knows what the new data field is, where it should live on a profile, and who to make that data point available to. This is where data engineers waste a lot of time on profile maintenance, and is a common problem with reverse ETL tools that need to be given permission to view datasets, tables, or views for every change. For example, you may have a customer table that has ten fields, each representing a different attribute. If you add an eleventh column, a reverse ETL vendor would not automatically expose it, since these tools only expose and track changes in columns in the original ten mapped fields that are part of the sync configuration. This type of challenge is typical when tools assume your data is already unified, when in fact it rarely is.
There are also challenges with accuracy when accounting for data changes. One common approach is to create new attributes using coding/SQL, as is usually the case with packaged CDPs, but the lack of universal ID across underlying data adds complexity to building attributes and can lead to inaccurate attribute values. Some products calculate attributes and generate insights in a data warehouse or off-platform through code, but if the CDP lacks historical data, calculated attributes will be off.
Finally, you need to account for multiple views of the data. Packaged CDPs typically offer every user the same view of the data, though their needs (and permissions) may be different. This gets even more complex when it’s multiple views across brands and geographies.

Change management is complex and risky
Updating data workflows takes forever because IT teams must work across multiple SaaS tools that lack any environment (let alone a unified one) for testing and monitoring. Most solutions force you to make changes in production, which puts downstream workflows at risk and makes rolling back changes extremely hard.
These challenges persist no matter what your approach to customer data is. Whatever your overall data strategy approach, you have a tech stack, and making all the pieces work together is no small feat.
Change management risks breaking or disrupting all downstream systems that rely on the customer data feeds. This is an obvious enough pitfall in the many tools that force you to make changes live in production. Another common approach is to create a copy production environment for testing, then map workflows to the copy, but that presents difficulty in rolling back changes if workflows fail. Finally, some opt to test changes in a non-production environment that only has access to some dummy sample data. This leaves you with a big unknown of whether workflows will work at scale when the sandbox is promoted to production.
Monitoring is often resource-intensive. There are typically two approaches: purchase additional software to monitor the end-to-end data workflow, or hire a team to monitor end-to-end data workflows across all of the disparate elements of a composable CDP.
Maintenance is complicated across multiple tools and environments. You need proficiency in every tool involved and have to go through each individual product’s support when issues arise. In a composable CDP, this could be up to five different platforms. Many opt to build and maintain an entirely separate development environment, which can be cumbersome.
Quality assurance is often manual and time-consuming. Standard approaches have no ability to mass pass/unpause when platform errors occur, and there’s no built-in alert system or tools to do quality assurance checks. You’re left to coordinate the workflow between these tools yourself.
Costs can quickly stack up. When a vendor is completely offloading their storage and computation to your data warehouse, incentives are misaligned. It’s to the vendor’s benefit to rapidly add new capabilities rather than optimizing their efficiency, and you get stuck with the bill.

Customizing tooling is difficult
Adding new technologies to your stack often traps data in silos or forces you into a specific way of working that’s difficult to customize for your business.
There are so many useful tools out there, and it would be great to put them all together to gain the benefit of their capabilities — tools for storage, data science & modeling, analytics, reverse ETL, and others. The problem is that these tools tend to be highly opinionated on how they work. That means there’s no common concept of “customer,” data risks getting trapped in more silos, and you can’t customize the underlying data model.
IT needs to make herculean efforts to get all the parts working together (and keep them that way). It’s often not as fast as intended because IT has to learn multiple systems and be able to pivot between them; it’s often not as cheap as expected since costs escalate as you scale. You end up constantly being at the mercy of how well your tech stack is performing.
What to look for to make customer data operations successful
I’ve laid out a host of problems here that brands commonly face when trying to handle their customer data operations. My goal isn’t to make you lose hope, but rather to help you understand the scope of the challenge.
We founded Amperity with the aim to help brands finally solve the foundational data quality problem that affects every single thing they want to do with customer data. In the process of building a platform to do this, we came to understand that the data quality problem requires so much maintenance and attention that can’t just be hand-waved away. We realized how hard this stuff is, and we devote all our time and energy to it — consumer brands whose main focus is making the best outdoor gear or providing top-notch hotel experiences or helping people achieve their financial goals shouldn’t have to worry about the million technical ways their customer data strategy could fall apart.
That’s why we built Amperity to answer all the pains of customer data operations. AI-powered, comprehensive identity resolution and a unified customer view with transparency, flexibility, control, stability, speed, and scale. Managing access for business users with multi-brand and multi-database views, role-based views, householding, and custom calculated attributes. Change management with 24/7 data monitoring and alerts, fully integrated live sandboxes for safe testing, and automatic data lineage and audit logs. Flexibility in the tech stack with data egress in any format, automatically-shaped data assets, modular functionality for interoperability, flexible data retention rules, and a cloud-agnostic platform.
Amperity makes customer data operations easy; it’s possible to do it in other ways, but you’ll probably find it’s a lot harder. That’s what we’ve heard for years from brands who have tried to do it on their own.
Either way, the key thing to account for is the size and complexity of the job to be done. Getting value from customer data, powering generative AI, making personalization work right — all of this depends on managing an end-to-end workflow pulling together massive amounts of data and multiple tools. And that just doesn’t happen on its own.