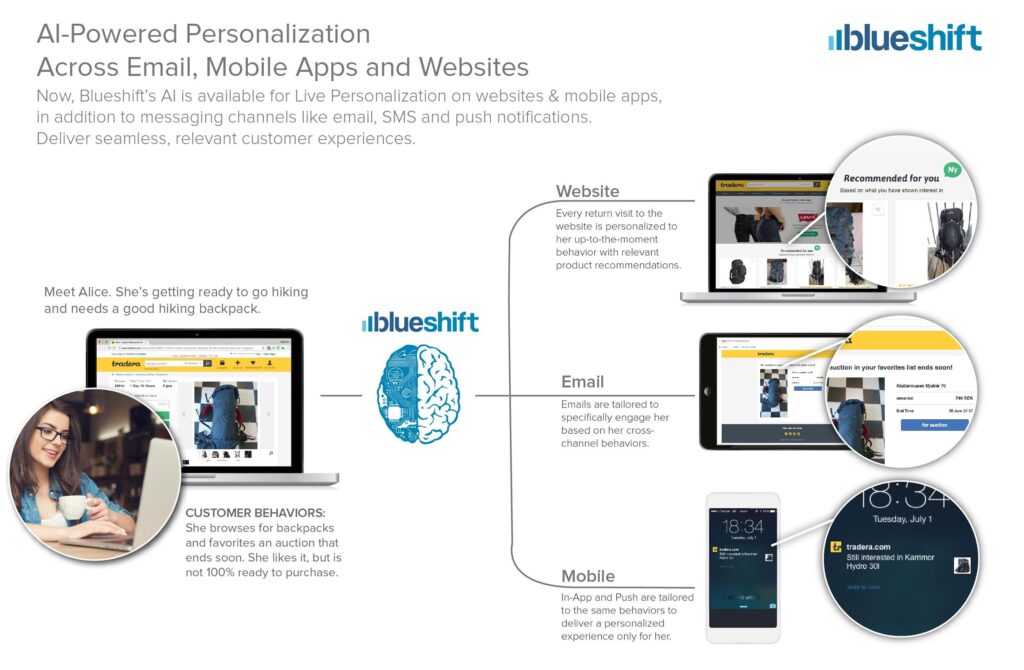
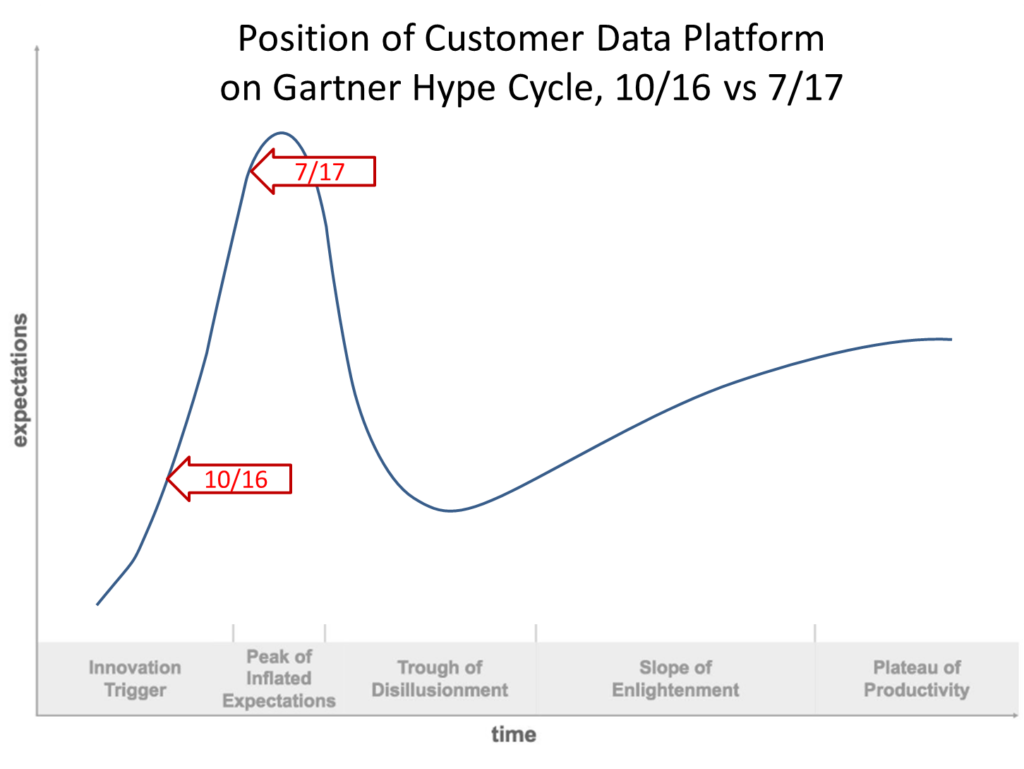
More on Classifying CDP Systems
September 13, 2017Last week’s post on classifying CDP systems yielded many insightful comments, both public and private. A few of the themes worth noting were:
– purpose of the exercise. Let’s start at the beginning: the goal of this exercise is to find a way to reduce confusion in the market about the many different types of CDPs. Both buyers and sellers suffer when marketers can’t easily figure out what different systems are good for, and thus which they should explore in detail as solutions to their particular needs. We’re not trying to gather all the information a marketer needs to make a choice, but rather to help marketers quickly narrow the field of products they consider. If we don’t do that, the marketers will soon decide the CDP label doesn’t mean anything useful and the category as a whole will suffer. That would be a loss since CDPs do provide capabilities that marketers might not otherwise be able to find, either because CDPs would be lumped into still broader categories (e.g. “data management”) or be ignored in favor of less suitable solutions that are more clearly defined (“marketing clouds”).
– type of information. Because the purpose is to help marketers understand roughly which systems are good for which purposes, we need to keep the whole scheme relatively simple. Yes, it’s possible to rate each vendor against a 400-point checklist (in fact, the Evaluation Guides in the Institute Library contain just that). But such reports are not useful to marketers just starting their selection process. Instead, they need a handful of items that help them to quickly understand the vendor landscape before they dive into the details.
– technology vs applications. Should a classification scheme be based on system technology or on applications? There’s no question that marketers buy applications. Most neither know nor care what goes on under the hood. But suitability for use cases is an extremely subjective measure. Many systems can be stretched to support use cases they’re not really designed for. If one of our goals is to find a classification system that vendors are willing to apply (or let the Institute apply), we need something that much less open to debate. Specific technical features are objectively present or not, although there are still plenty of nuances. Technical features also tend to reflect a system’s original design goals, which are themselves usually applications. So there’s a broad correlation between technology and applications, which should be enough to guide buyers in the right directions. Moreover, a few critical technical features will correlate with many capabilities. So if we pick wisely, we should be able to keep the amount of information at an easily digestible level.
– vendors in multiple categories. There was some confusion among readers but my intent in the original post was that one vendor could belong to several categories. It still is. This could be true whether the attributes relate to technology or to applications: some technologies are compatible without being mutually required; similarly, some applications are independent of each other. More concretely, a system that’s good at resolving postal addresses might or might not also be good at cross-device matching. Each task uses technologies that are different but don’t conflict. Marketers who need one, the other, or both types of matching could look at systems with the right technologies to quickly find the ones that might meet their needs (or, more to the point, to exclude systems that don’t meet their needs). It’s true that vendors will want to be in as many categories as possible, even if they just marginally qualify. That’s where using relatively objective technical criteria makes things so much easier. So I think it’s a manageable problem.
So far so good, but this is just warming up to face the real question: what should the categories be? I proposed one set last week but didn’t consider it final. The feedback from that post included a good number of recommendations for other categories and ways of organizing the categories. I started from scratch by listing the items suggested and seeing what clusters felt natural. Three dimensions emerged these were:
– activity supported. Some items related to building the unified customer database itself, some to sharing the assembled data, some to analyzing it, and some to selecting customer treatments (a.k.a. campaign management, decisions, or orchestration). Those felt like distinct enough categories to be treated separately, even though there’s some overlap, especially between analysis and treatment selection. There were yet other items that related to vendors, such as pricing and services provided. Rather than lose them, I gave them a category of their own.
– data type. There were some items that clearly related to online data, such as capturing Web or mobile transactions. There were others that related to “big data”, such as use of NoSQL technology. A couple more related specifically to B2B or offline data. The rest seemed to apply to pretty much everyone so I not-very-creatively labeled them “general”.
– specificity. Remember that my strategy is to find specific items that can easily and objectively be judged as present or not. About half the items fell into this category, either inherently or because we could add specifics such as having prebuilt connectors to certain key systems.
A table with the results is at the end of this post. I’ve highlighted the different categories to make things a little easier to see. A few observations:
– nearly half the items relate to building the database. That’s good. After all, we’re talking about Customer Data Platforms, so the differences in how they handle data is our main concern.
– Most of the variations in data type also fall into the data category. Again, that’s good news since it means we have a good chance of finding markers to identify the different types of systems.
– Nearly all the data build items are specific. That’s great. The sharing category is also in pretty good shape. Analyze and treat are mostly general, but those are categories where not every CDP competes, so it should be easier to make broad judgements about who’s in. Vendor categories are really outside the scope of this exercise. Buyers can screen on them after they’ve figured out which systems meet their technical / functional needs.
– Excluding the vendor group, there are ten unique combinations of categories between the first two columns (build/B2B, build/big data, build/online, etc.). Those could become ten clusters. No cluster has more than eight line items and most have fewer, which is quite manageable. The total of 48 rows is a few more than I wanted but we could probably get rid of some. All very promising.
These clusters don’t match the ones I offered last week. That’s perfectly fine. Nor do I think this is the optimal set. But I think it’s moving the discussion forward. The next step is to get more feedback from the CDP community (that’s you) and to start tightening up the definitions of the individual items so we can make the data collection and presentation as straightforward as possible.
I look forward to hearing your thoughts.