What is the cost of poor quality data?
January 12, 2023Raise your hand if you’ve been personally victimized by bad data. I know I have. There are 2.5 quintillion bytes of data created each day. That’s a lot! This data is created constantly – from the websites we visit, to hours watching our favorite Netflix shows, posts and views and likes on Instagram, data is created all the time. With a number like 2.5 quintillion, there’s bound to be some mistakes in there.
By mistakes, I mean bad, poor quality data – information that is inaccurate, incomplete, non-formatted, irrelevant, or duplicate. Throughout this blog, I will reference these terms interchangeably, but keep in mind that they each pose their own unique set of problems.
It’s very easy to create inaccurate data. Maybe you made an online alias to download a quick PDF, or you might have a finsta account. Or maybe you just made a typo when submitting a form. And while innocuous, this mis-information has a dollar amount attached to it.
IBM estimates the yearly cost of poor quality data in the US is $3.1 Trillion (that’s with a T). So if you think your company is without bad data, you most likely just haven’t found it yet.
I did it “My Way” and the computer didn’t understand
To expand upon the second sentence of this blog, I too have experience with poor quality data. To set the scene, I emailed all of our customers living within the United States and invited them to a big event. A very important customer, I’ll call him Vic, never received my email invitation. I found this out when a member of our Sales team stopped by my desk (remember those days?) and asked why I had excluded Vic from the invitation.
Confusion ensued, which led to one of those, “Stop what you’re doing and let’s figure this out ASAP” troubleshooting moments. Maybe Vic unsubscribed, or maybe the CRM’s servers were down. Did I even send the email?
To speed the story up, we dug into our CRM database and discovered that Vic’s country was written as “USA.” The email invitation I sent out was set to the list of customers based off the field, “Country field contains ‘United States.’”

Now, I know that the United States is also called the USA, but my system didn’t. The fact that we had so many different entries for the same country in the same field meant we had a dirty data problem. While unfortunate and time consuming to work through, the root cause of this dirty data isn’t unreasonable.
Some of our customers entered our CRM from webforms where the country field was selectable from a drop down list. Others came from scanning badges at live events, where there was no standard way to enter your country. We had customers enter our system from webinars, blog subscriptions, and even SDRs manually inputting entries into our CRM.
Poor quality or non-standardized data affects marketers because it affects the way they communicate with customers.
Let’s dive into the real world impact of marketers relying on poor quality data.
The effect bad data has on marketers
According to our 2022 “State of Personalization Report”, 62% of consumers say a brand will lose their loyalty if they deliver an un-personalized experience. This puts more pressure on marketers to send the right message, customized to each unique customer.
Sending incorrect messages to a customer hurts their relationship with your brand. When you send an email to the wrong list (ex. Inviting Australian customers to an event in Vienna) you run the risk of falling into a spam trap. The more low quality emails you send, the higher your email churn rate because customers lose interest and have a sub-par experience.
Disinterested customers are only the tip of the iceberg. When you start to lose your customers’ trust, it erodes the value of your brand. If your customers view your content as arbitrary or worse, annoying, they will unsubscribe or take their business elsewhere – maybe to your competitors. Don’t forget that new customers cost 5 times more than retaining existing customers. It’s better to not risk losing your loyal customers.
Marketers work very hard to build trust in their brand. Once trust is established, they can have fun experimenting with new campaign ideas. They deserve better than to have their hard work be usurped by bad quality data.
But what about the data scientists?
Bad data doesn’t only hurt the reputation of marketers through their customer interactions. It also affects the internal workings of an organization as well, which has deep seeded consequences.
Forbes shared in 2016 that data scientists spend 60% of their time cleaning and organizing data.
I think we’d all agree that companies are paying top dollar for data scientists to solve complex problems and find forecasts. This 60% cleaning and organizing data takes away from their other, more unique roles. Sure, they can clean small amounts of data on the fly, but this can take minutes or hours depending on the complexity of their systems and if they can spot the inconsistencies before they go downstream.
Once the dirty data is downstream, it can wreak havoc on their models. Any charts created are going to reflect this bad data. Imagine a bar chart of countries, where you have one bar for the USA, and one for the United States. Sure, any data scientist with an understanding of world geography might catch this error before it’s presented and resolve it themselves. But how about when the mistakes aren’t so obvious?
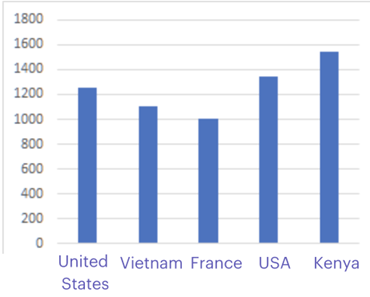
The way the data scientists present the models can be compromised by the bad data. This is a bad look internally for the data science team, as stakeholders may begin to doubt these projections. Despite the word “data” literally in their name, data scientists can’t be expected to perform magic and create accurate charts when the data itself is of poor quality.
When companies make decisions based on bad data, it affects the organization’s bottom line- predicted revenue drops, expenses rise, and trust is lost in the data science department.
How bad data costs a trust and cost deficit for your engineering team
Data governance plays a particularly important role in engineering organizations. As more teams within an organization can handle and pull data internally, there is less data governance and more room for error. This creates a vicious cycle around your engineer.
Consider this, your data analyst notices that Tool A and Tool B, which both analyze data from your system, have inconsistent results. They extract a spreadsheet of this data from both tools, and manually highlight discrepancies, and bring it to the engineers. Now the engineers and data scientists must spend time proving that the data is correct, or finding a bug in it.
Imagine the joy when, 3 hours of research later, they discover that the error is caused because there are 2 “phone number” fields and the data analyst grabbed the wrong one!
The more complex your tech stack, the higher the chances are of bad data entering the stack. And it becomes more expensive to resolve these issues the farther down the mistake gets. Without standardized data input, extra cells are added into your data warehouse.
In a relational database, you’re provisioning a column that will be largely empty. Say most of your forms ask for a phone number (value phone-number) and only one asks for a home phone (value home-phone). When you introduce the value home-phone to the data warehouse, every single customer in the system will now have a field, home-phone, added to them, which will mostly remain blank. You are allocating memory and storage space for empty fields. (And yes, noSQL databases may alleviate some of these concerns about storage costs. But if your stack is built around traditional RDBMS, you’ve got capacity planning issues.)
Errors in the data warehouse exist in production environments, too. If you’ve ever caught a surprisingly cheap flight, you’ve benefited from bad data while causing turmoil for airlines. Often dubbed “mistake fares” they occur when the data in a warehouse churns out incorrect numbers. Airlines can either honor these fares, or revoke them and charge the customer the difference. This not only angers the customer, but it requires an engineer somewhere to frantically try to pinpoint and resolve the issue with the data.
The travel industry has bold examples, but similar errors are lurking in almost every company’s data.
How can a CDP help with bad data?
Fortunately, bad data is not a problem without a solution. A Customer Data Platform, like Twilio Segment, acts as the central hub for your team’s data collection. Data is gathered once and presented equitably to all the downstream destination tools in real time.
Segment’s Tracking Plans feature allows you to define the rules around what events you anticipate collecting from all of your sources. It takes time, effort, and a strong understanding of your business objectives, to build these plans. Once they are created, all of your teams are on the same page for one point of reference/source of truth for the data they are consuming.
Tracking Plans lets you validate the expected events against live events delivered to Segment. Violations will occur when an event doesn’t match the spec’d event in the tracking plan. In Segment, you can dig in to see the violations and what caused them. It’s a quick way to debug if you see issues in the downstream tools.
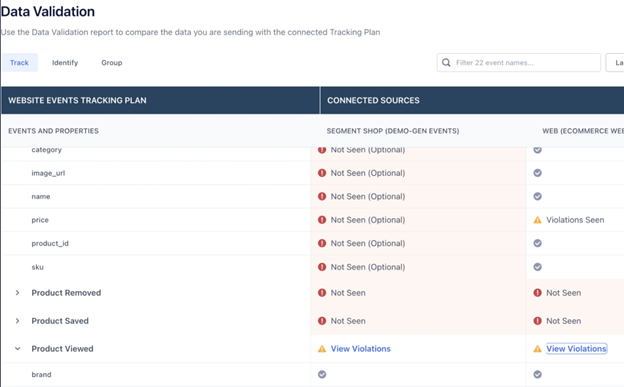
You can also stop events from hitting your downstream tools all together.
Let’s say you implemented an event with a typo in it. Segment gives you the option to send the event and forward it to different places to be cleaned, and later replayed, to ensure there is no data loss. You can block the properties that don’t match the spec, or block the entire event. With Segment’s Transformations feature, you can transform event names, properties, and more just in case you spot a mistake in production. Essentially, you’re transforming events “mid flight” to conform to your standard.
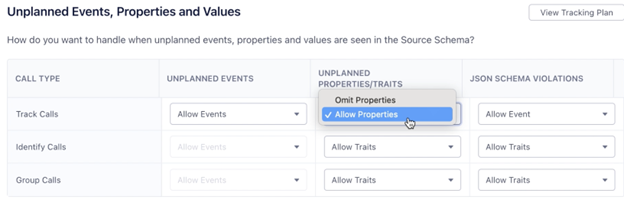
We’ve focused on how Segment processes this data in real time. It can also collect historical data. Segment offers a replay feature, which takes an archived copy of your Segment data and re-sends it to your downstream tools.
Replay prevents being locked in to any vendor that you’d otherwise be afraid to leave because of all the history you’ve accrued in that tool. Once you set up any new tool, you can pull in the historical data immediately, you don’t need to wait for it to collect over time. And engineers don’t need to worry about data migration from one tool to the next, which lowers the cost of implementing new tools.
Segment’s CDP provides tools to both save your team in the debugging process, and flag violations in real time to prevent frantic cleaning up. Watch the video below to see how Segment ensures data quality:
Wrapping up
None of us are immune to bad information sneaking into our datasets. Identifying and resolving this bad data costs your marketers, data scientists, and engineers time and effort. It also diminishes the trust your customers have in your company.
Companies that invest in a CDP have a clear path to ensure that data is up to standard, and looks as expected. Clean data leads to stronger business decisions, more personalized marketing campaigns, less workarounds.


